前言
本文介绍首个将VQ-free推广至视频生成的NOVA。我们之前介绍了VQ-free的图像生成工作MAR:
其中用双向transformer建模前缀信息$z$,而后将其作为控制信号用轻量级diffusion建模masked token分布从而生成。推广至视频生成领域,则需要将历史帧和本segment内的token联合时空建模,再接diffusion,沿着这个思路就是我们今天介绍的NOVA了。出自《Autoregressive Video Generation without Vector Quantization》,将图像视作单帧视频,支持T2I、T2V、I2V等任务。目前已开源T2I、T2V的推理,后续也计划开源train和eval代码,值得期待。
Pipeline
首先需要明确NOVA的生成单元。首先视频经过一个3D-VAE在时空上分别进行4、8倍的压缩。同时时序上为单帧生成,而对于每一帧则和MAR一样也是next set-of-tokens generation。正如我们所述的,NOVA将视频生成拆解为了时间上的逐帧预测和空间上的逐集预测:
We propose to reformulate the video generation problem as a non-quantized autoregressive modeling of temporal frame-by-frame prediction and spatial set-by-set prediction.
整体流程如下图所示。

我们再来看输入,首先有做T2V的文本prompt$P$;此外为了在推理时能控制视频动态,NOVA在训练时将视频光流的平均值$m\in\mathbb R$作为输入;序列开头为特殊token[BOV],记为$B$。设共有$F$帧,每帧为$K$个token的集合$S_f=\{s_{f,1},\cdots,s_{f,K}\}$。
在时序角度上的生成行为即是逐帧的casual生成:
$$ p(P,m,B,S_1,\cdots,S_F)=\prod_{f=1}^F p(S_f|P,m,B,S_1,\cdots,S_{f-1}) \tag{1} $$
也即将每帧的tokens加上1D的sinusoidal位置编码再过一个casual transformer,这样虽然提取前缀帧信息的能力不如双向注意力,但能应用kv-cache加速技巧。从任务拓展上,T2V可以表示为(1)式;而T2V可以表示为$p(S_1|P,m,B)$;而I2V可以表示为$p(S_f|\empty,m,B,S_1,\cdots,S_{f-1})$,V2V也同理了。
接下来就是帧内部的生成了,总体上是MAR的思路,到NOVA这里就是用历史帧信息$z_f$+已生成的token:$s_{f,1},\cdots,s_{f,k}$经过spatial transformer+轻量diffusion来建模下一组待生成token的分布:
$$ p(z_f,s_{f,1},\cdots,s_{f,K})=\prod_{k=1}^K p(s_{f,k}|z_f,s_{f,1},\cdots,s_{f,k-1})\tag{2} $$
历史帧信息$z_f$有个细节需要注意,作者认为如果直接用temporal transformer的最后一层特征会导致严重的误差累积;而且实验发现这样会导致严重的图像结构崩溃和时序连续性的问题。作者认为这是由于最后一层特征在相邻两帧间比较类似,难以表征时序动态。
针对这两个问题,作者用[BOV](时序上第一组token)和temporal transformer的特征进行AdaLN组合得到前缀约束信息$z_f$:
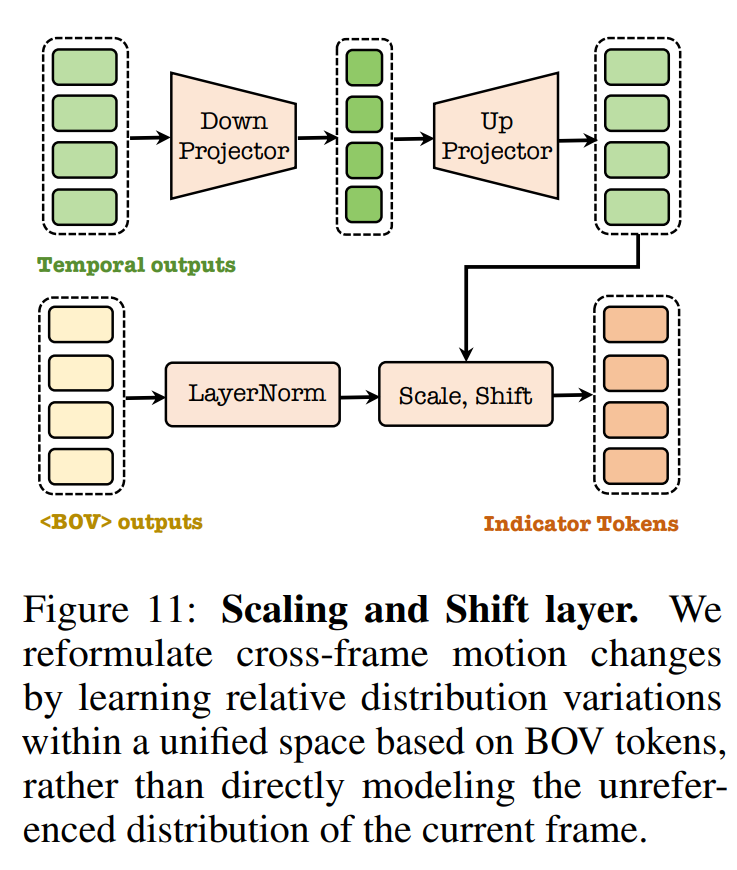
而后就是常规的加入2D位置编码的spatial transformer和diffusion loss了,与MAR是一致的。
实验结果
首先是T2I的指标结果。在几个benchmark上都取得了比较SOTA的结果。

而在T2V的VBench上和最SOTA的Emu3相比也有一战之力,当然论文中说的significantly suppresses the AR counterpart有点夸张了。

在定量生成结果展示上,笔者试了一下huggingface的demo(1024*1024),T2I的效果还算ok(当然和FLUX、Emu还是有点差距的):

而T2V的结果就比较一般了,下面是一个示例(prompt:An elephant slowly walks out of a cloud of fog, the fog shatters and flows)。整体算是开源工作中第二梯队的水平吧。
总结
NOVA在保持MAR的框架上加入了历史帧的时序信息,时序和空间中的连接层也有一定的创新,不过感觉时序前缀信息粒度有点粗了,而且是逐帧生成,效率肯定不如逐segment的。
References
- Autoregressive Video Generation without Vector Quantization, arXiv - NOVA
Haoge Deng, Ting Pan, Haiwen Diao, Zhengxiong Luo, Yufeng Cui, Huchuan Lu, Shiguang Shan, Yonggang Qi, Xinlong Wang, 2024.12 | arXiv PDF
