Audio-Driven THG(三):Hallo与Loopy
前言
本文介绍两篇影响力比较大的工作Hallo和Loopy。由于Hallo的训练和推理代码全开源,因此后续我们也会详细学习一下其代码。
Audio与Motion
回顾之前介绍的三个工作:
运动信息要么是加在输入的noise上,要么是加在一个attention层上;而音频信息则是用cross-attention加入。然而将audio和motion信息分别加入denoising net里不能很好刻画音频-运动-ID之间关系,头部运动应该和音频之间有一致性。沿着这个idea,学界提出了两篇工作:Hallo和Loopy。
Hallo
在音频与运动一致性建模方面,Hallo直接从视觉角度出发,将audio信息与面部的各个位置的信息相混合。作者选择了三个区域:lip、expression和pose,具体而言首先检测嘴部和面部的landmark与location框:$Y_{lip},Y_{exp}$,而后计算mask:
$$ \begin{align} M_{lip}&=Y_{lip}\\ M_{exp}&=(1-M_{lip})\odot Y_{exp}\\ M_{pose}&=1-M_{exp} \end{align} $$
其中$\odot$为Hadamard积。相当于lip就是嘴部;expression是面部除了嘴部的部分;而pose是整个图片除去expression的部分,虽然带有一定的背景信息,但也把头发、头饰、肩膀部分考虑进去了。下图可以更好地说明这三个部分关注的区域:
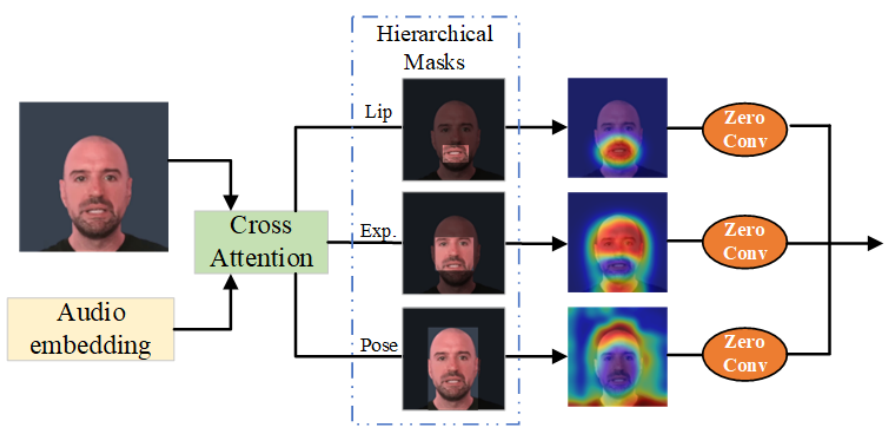
注意到:$M_{pose}=1-M_{exp}=1-Y_{exp}+M_{lip}\odot Y_{exp}$,按理说$M_{pose}$应该有lip的信息,不过图中没体现出来,而且直观上也不太合理。私以为$M_{pose}=1-Y_{exp}$更好。
而后我们首先将denoising net的feature和audio特征做cross-attention得到$o_{t}$;再分别加上mask:
$$ b_t=o_t\odot M_{pose},\quad f_t=o_t\odot M_{exp},\quad l_t=o_t\odot M_{lip} $$
而后分别加一个zero-conv(ControlNet的零卷积)再相加作为audio-motion的统一特征。
除此之外Hallo的改进就不多了:

spatial attention和temporal attention没有改动,只是原来第二个attention是用reference net的特征与denoising net特征做cross-attention,这里额外用一个encoder提取面部特征,再分别cross-attention加入到reference net和denoising net里,难道是觉得只用reference net提取人脸特征不够好,额外引入其他的特征?文中也没有做消融,只能这么认为了。
总体看下来,显式地考虑audio与motion之间的关联是一个很好的思路,没有去考证talking head领域里Hallo是不是第一个考虑这一点的,24年确实没有注意到相关工作。不过方法上还是有讨论空间的,在pixel或者feature map上加上mask就可以对齐audio-motion空间吗?多层次feature之间直接相加感觉有更好的fuse方式。同时额外使用一个face embedding的作用也值得商榷。
Loopy框架
接下来我们来看Loopy:

核心的改动是用inter/intra-clip attention换掉了之前的temporal attention;弱控制信号为translation和expression。
在之前介绍V-Express和EchoMimic时我们也提到其时序模块是将之前的$n$帧(实际为4)的reference net特征图与denoising net特征各自reshape后再时序维度拼接,再self-attention。然而这种时序机制在每次生成$f=12$帧时总共只能cover$f+n=16$帧,也即30FPS下的0.5s,这样导致模型从motion frames里学到的更多是appearance信息而不是motion信息。文中举了个例子:0.5秒的先前信息不足以让模型确定是否应该眨眼,所以眨眼成为了一个概率事件,可能导致不真实。进一步地,作者发现如果单纯地增加motion frames的数量一定程度上可以生成幅度更大的运动,但是不稳定性会增加,因此在时序关系上需要更长时的刻画。
同时Loopy也对音频和运动信息的处理也进行了改进,既然直接加入不好,那就显式地对齐audio和motion两个模态再注入,接下来我们详细介绍一下。文中有一些细节写得不是很清楚,笔者加入了自己的理解,如果有错误还请读者指正。
Inter/Intra-clip attention
首先盘点一下我们在时序模块能用上的东西:reference image以及其经过VQ-VAE的latents:$c_{ref}$、之前$m$帧的motion frames latents:$c_{mf}$、时间步$t$,以及denoising net的feature。作者设计了两种时序机制:inter-clip用来捕捉当前生成的segment(也就是文中的clip这个词,笔者更喜欢用segment表示一起生成的$f$帧,而clip表示视频片段)与之前生成的之间的时序关系;而intra-clip用来刻画当前segment内的时序关系。
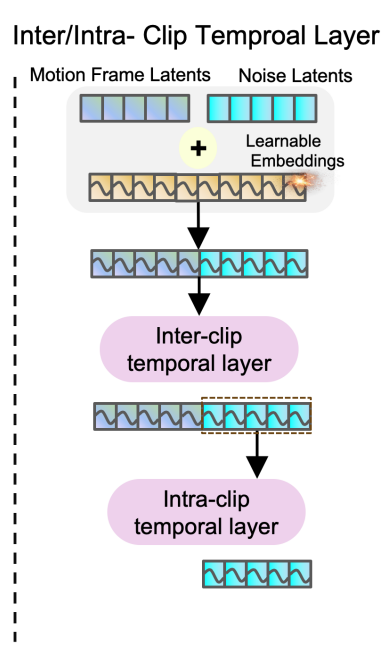
Inter/Intra-clip attention如上图所示,这里文章把latents和feature混用了,事实上这里先是将motion frames latents的reference net feature和denoising net feature在时序维度拼接,再加入时间步的embedding后做self-attention,而后取后半部分在做一次self-attention。做法与之前相当于是增加了segment内的时序注意力,而最核心的改动是这里进入reference net的motion frames latents。
我们在上文中提到单纯增加进入时序模块的motion frame latents数量效果并不好,而且由于之后要self-attention,计算资源的限制也不支持非常长的motion frame features。因此作者将进入reference net的motion frame latents进行了压缩,称为Temporal Segment Module也就是方法图里的TSM:

对于之前的$m$个motion frame latents,一个直观的想法是距离当前segment越近的越重要,越要保留,而越远的只需要保留几个就够了,因此作者设计了一个分段的方法:$s\times r^{(t-1)}$,设$s=4,t=2$时,第一段即1至4共4帧;第二段即4至12共8帧……而在每段内重复取最中心的帧$s$次,比如在刚刚的例子中,最后压缩的帧index就为:2、2、2、2、8、8、8、8……这样一共就将$m$帧压缩到了$t\times s$帧。实际中$t=5$,因此$m=4+8+16+32+64=124$,而压缩得到的$c_{mf}^o$长度为20。这样相当于对之前的motion frames手动进行了一个1D卷积,从而将窗口从$m=4$拓展到了$m=124$约4s。
这一部分说实话有一些疑问,整体思路还是比较直观清晰的,但是为什么在每段内取的是固定index的帧呢?在每段内均匀取$s$帧不是更好么?搞一个可学习的1D小卷积层如何呢?
Audio Condition Module
看完了时序部分,我们再来看Loopy的第二个改进:Audio condition module。首先和Emote Portrait Alive一样首先过Wav2Vec,再拼接前后两帧的特征得到基本的audio特征。进一步地作者认为如果将audio和motion信息分别通过cross-attention加入到denoising net里不能很好捕捉音频-运动-ID之间的关系,例如运动不能很好体现音频节奏等等,因此作者首先将音频与motion信息进行fusion:
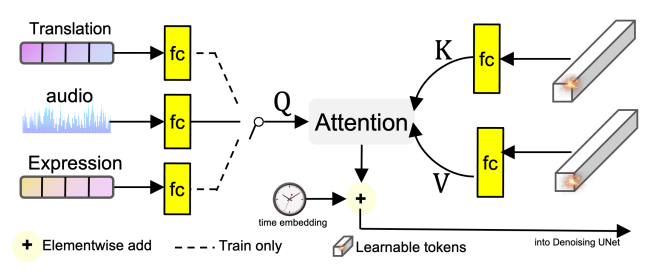
motion信息方面Loopy使用的是比较high-level的translation和expression:首先用DWPose检测这个segment的keypoints,然后用鼻尖绝对位移的方差作为translation信息;用上半张脸关键点相对鼻尖的位移的方差作为expression信息,而后过FC(按图中所示应该是吧),最后这三者各以1/3的概率做为$Q$,和一个可学习的$K,V$做cross-attention,再加上Diffusion的time embedding作为$K,V$,而将noise latents作为$Q$,将输出的feature作为denoising UNet的输入。作者认为通过这样概率选择的方式与cross-attention,模型可以学习一个audio-motion的联合空间。
这里还有一个细节笔者感到疑惑,audio feature的shape应该是$b\times f\times 5\times d$,而translation和expression过一个FC后应该是$b\times d$,回顾attention的计算:
$$ Q\in \mathbb R^{b\times l_q\times d_k},K\in\mathbb R^{b\times l_k\times d_k},V\in\mathbb R^{b\times l_k\times d_v}\to O\in\mathbb R^{b\times l_q\times d_v} $$
考虑到最后输出的shape应该是一样的,所以audio要reshape到$b\times f\times (5d)$,translation和expression应该也要repeat到$b\times f\times d$,但是这样感觉不是特别优雅,还是说translation和expression并不是定值而是一个序列?
Conclusions
最后就可以把这几个部分组合起来了,还有两个点需要注意:作者引入了Audio Condition Module之外并没有删除audio attention,此外denoising UNet也没有用之前的self+cross,而是采用了Animate Anyone中的spatial-attention。
总体说来还是一篇相当优秀的工作,从idea到模型到实验都比较自然流畅,强烈推荐大家去官网看看demo。由于有更长时的时序建模以及audio-motion的混合,头部运动和audio比较贴合,特别是一些配饰比如耳环之类的运动非常自然,不得不佩服作者功力之深厚。
总结上述的两个工作,二者的核心idea都是显式地建模音频与运动之间的关联,Hallo在pixel和feature map上加入mask;而Loopy则用训练去对齐了这两个模态的空间。总体而言是一个很不错的idea,后续改进可能一个是用更优雅的方式模态对齐,再一个就是由于这两个工作基本上绑定了audio和motion,因此只能用CFG去调整motion的运动幅度和多样性,但这不可避免地会影响到audio和口型,因此训练时对齐、推理时分开控制也是一个比较重要的点。
接下来我们详细学习一下Hallo的代码。
References
- Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation, -Hallo
Mingwang Xu, Hui Li, Qingkun Su, Hanlin Shang, Liwei Zhang, Ce Liu, Jingdong Wang, Yao Yao, Siyu Zhu, 2024.06 | arXiv pdf Project homepage Official Implementation - Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency, -Loopy
Jianwen Jiang, Chao Liang, Jiaqi Yang, Gaojie Lin, Tianyun Zhong, Yanbo Zheng, 2024.09 | arXiv pdf Project homepage

1 条评论
棒